KAN

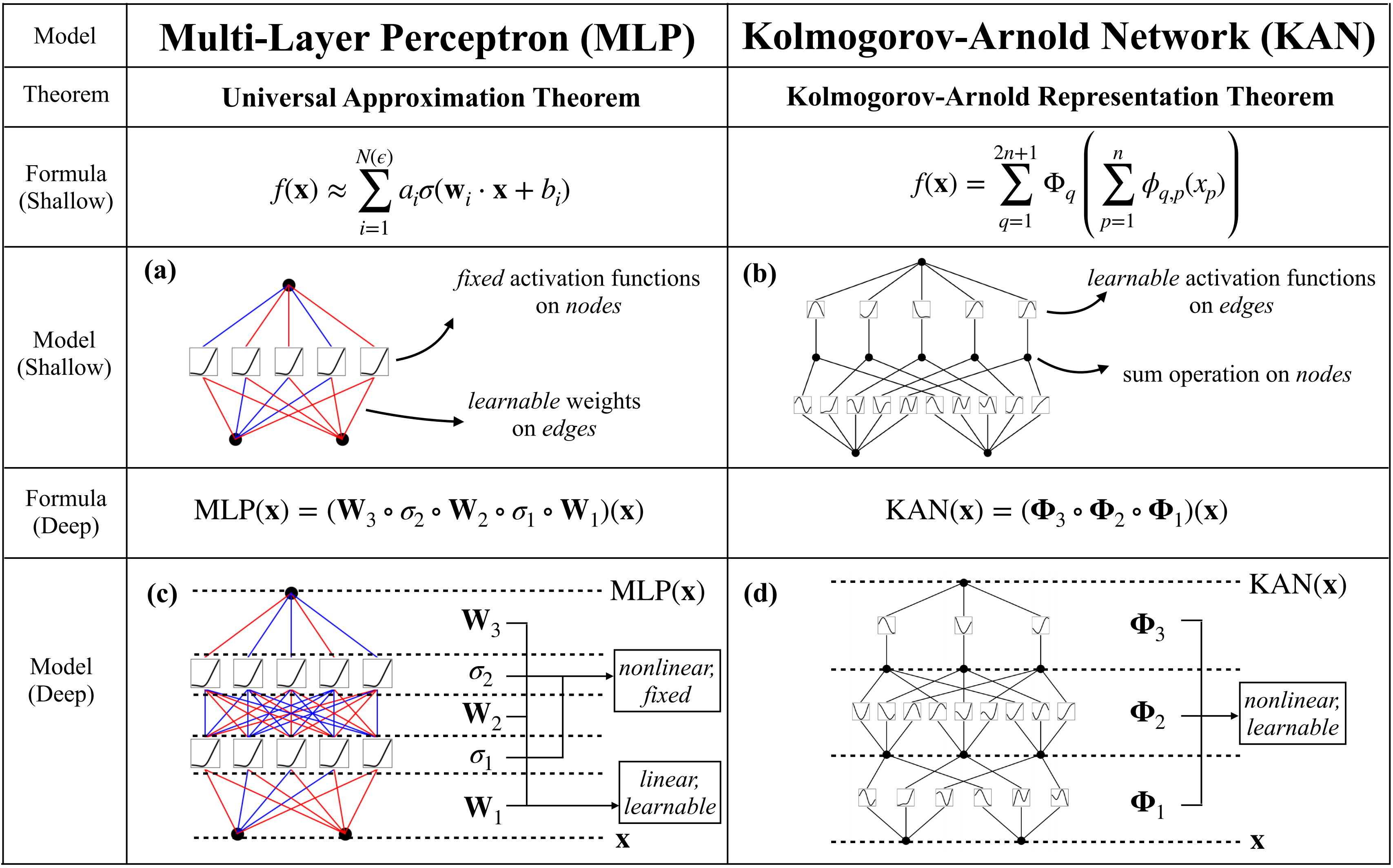
现在我们有了 KAN 的原型,其计算图完全由方程式(2.1)指定,并在下图(b)中进行了说明
- 输入维度为 2,呈现为一个两层神经网络
- 激活函数放置在边edges上而不是节点nodes上(节点上执行简单求和),中间层的宽度为2n+ 1
对于一个光滑
-
由于论文中没有细致指出每一个变量的含义,但考虑到本文追求的详尽、细致的缘故,故我补充解释一下,其中各个变量的含义
其中,即代表向量 的第 个元素,故 的范围是从 到 ( 是输入向量的维度)
这个索引用于遍历外部函数 的每个组成部分
故有一元函数(或称单变量函数)处理输入向量 的第 个分量,并为第 个外部函数的求和贡献一个项 定理指出,你可以用 2n+1 个这样的外部函数——每个外部函数
是一个一元函数(它作用于由内部一元函数 的输出组成的求和),来表示任何多变量函数 -
总之,每个函数都可以用一元函数和求和来表示(since every other function can be written using univariate functions and sum),看似前途一片光明,因为学习高维函数可以因此归结为学习多项式数量的一维函数(learning a high-dimensional function boils down to learning a polynomial number of 1D functions)
然而,这些一维函数可能是非光滑甚至是分形的,因此在实践中可能无法学习(However, these 1D functions can be non-smooth and even fractal, so they may not be learnable in practice)
原方案
在MLPs中,一旦我们定义了一个层(由线性变换和非线性组成),便可以堆叠更多层使网络更深
类似的,要构建深层KANs,首先要回答:“什么是KAN层?” 原来,具有输入维度和输出维度的KAN层可以被定义为一维函数矩阵(定义为公式2.2)
其中函数ϕq,p𝜙𝑞,𝑝具有可训练参数
-
在Kolmogorov-Arnold定理中,先“散”后“聚”
内部函数形成一个KAN层,其中输入维度 ,输出维度
这表明每个输入变量通过一组函数转换,输出的数量是输入数量的两倍加一,这样设计是为了充分捕获输入特征的信息并转化为中间表示
外部函数{\Phi_q}形成一个KAN层,其中输入维度,输出维度
这层的功能是将内部函数层的所有输出整合起来,形成最终的模型输出因此,方程2.1中的Kolmogorov-Arnold表示简单地由两个KAN层组成
-
现在清楚了什么是更深层的Kolmogorov-Arnold表示:简单地堆叠更多的KAN层
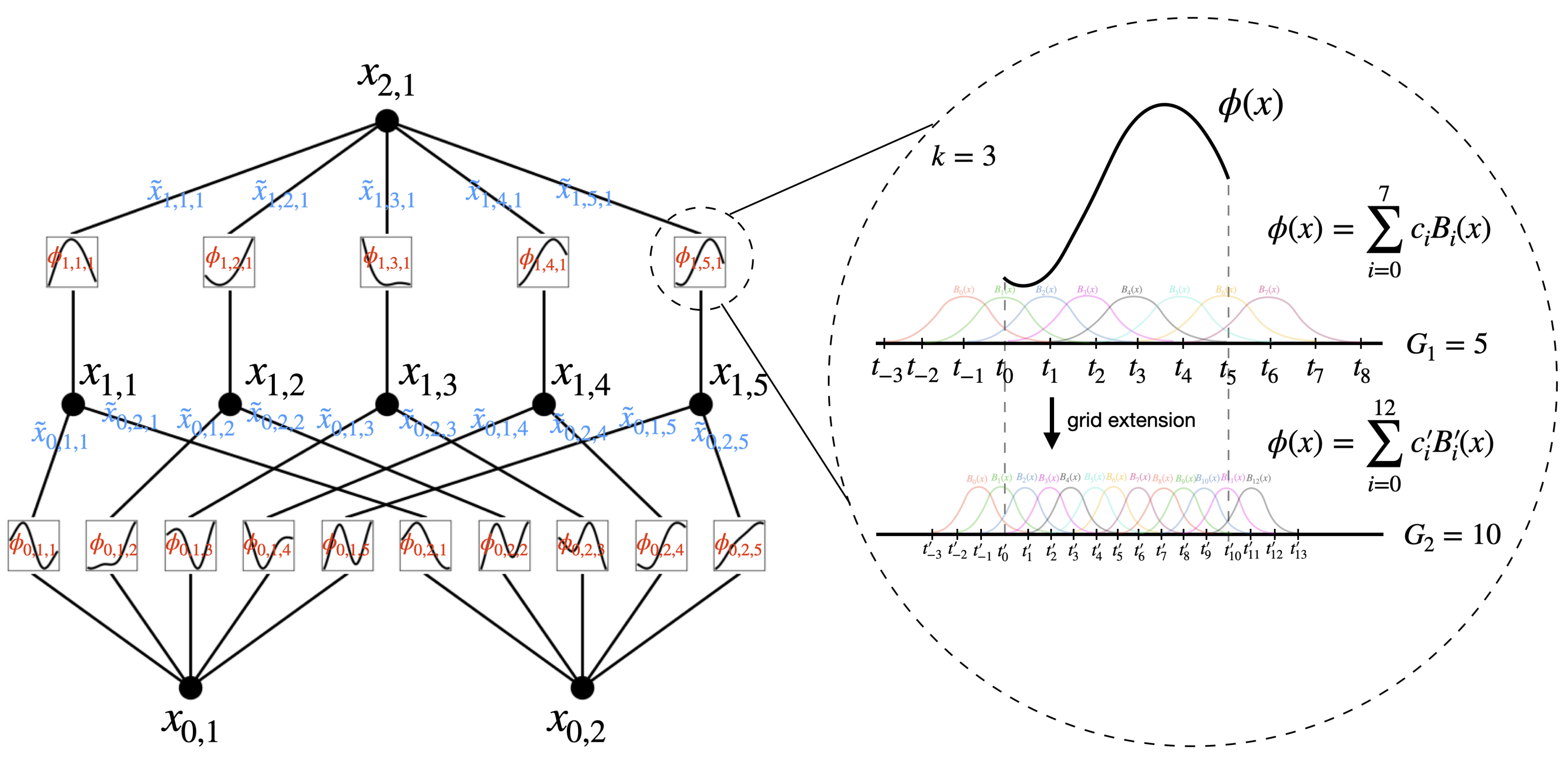
现方案
- 其中
是计算图中第 层节点的数量(比如当从0开始计数的话,上图第1层总计5个节点)
且用表示第 层的第 个神经元(比如上图 表示第1层第2个神经元)
并用表示 -神经元的激活值
在第层和第 层之间,有 激活函数(从第1层到第2层, ,则总计有5×1个激活函数) - 连接
和 的激活函数用下述公式表示(比如 )
的预激活简单地是 ,即
的后激活用 表示,
第神经元即 的激活值简单地是所有传入后激活的总和(定义为公式2.5)
- 以矩阵形式表示,这可以写成(定义成公式2.6,注意,一列一列的竖着看)
其中,
-
一般的KAN网络是由 L𝐿层组成的:给定一个输入向量
,KAN的输出是(定义为公式2.7)
最简的KAN则可以写为:
-
还可以重写上述方程,使其更类似于方程2.1,假设输出维度
为1,并定义
异同
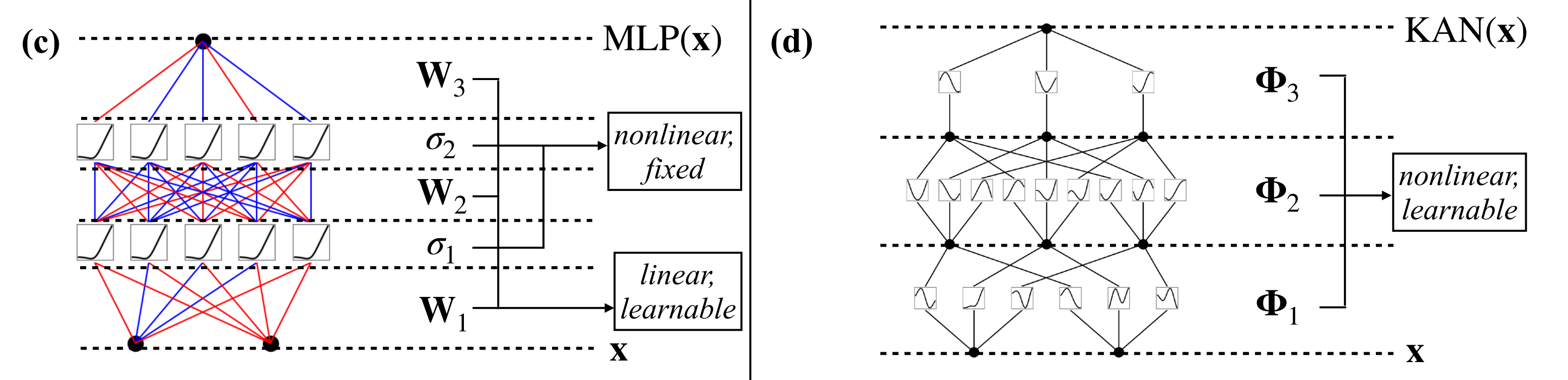
类似的,MLP也可以扩展到比较深、宽,比如写成仿射变换 W和非线性 σ的交错
很明显,MLPs将线性变换和非线性分开处理,分别表示为 W和 σ,而KANs将它们全部合
并在
总结一下
- 与MLPs类似,KANs具有全连接结构
- 然而,MLPs在节点——「神经元」上具有固定的激活函数,而KANs在边——「权重」上具有可学习的激活函数,如下图所示
因此,KANs根本没有线性权重矩阵:相反,每个权重参数都被可学习的一维函数取代,参数化为样条函数
且KANs的节点只是简单地对传入信号求和,而不施加任何非线性