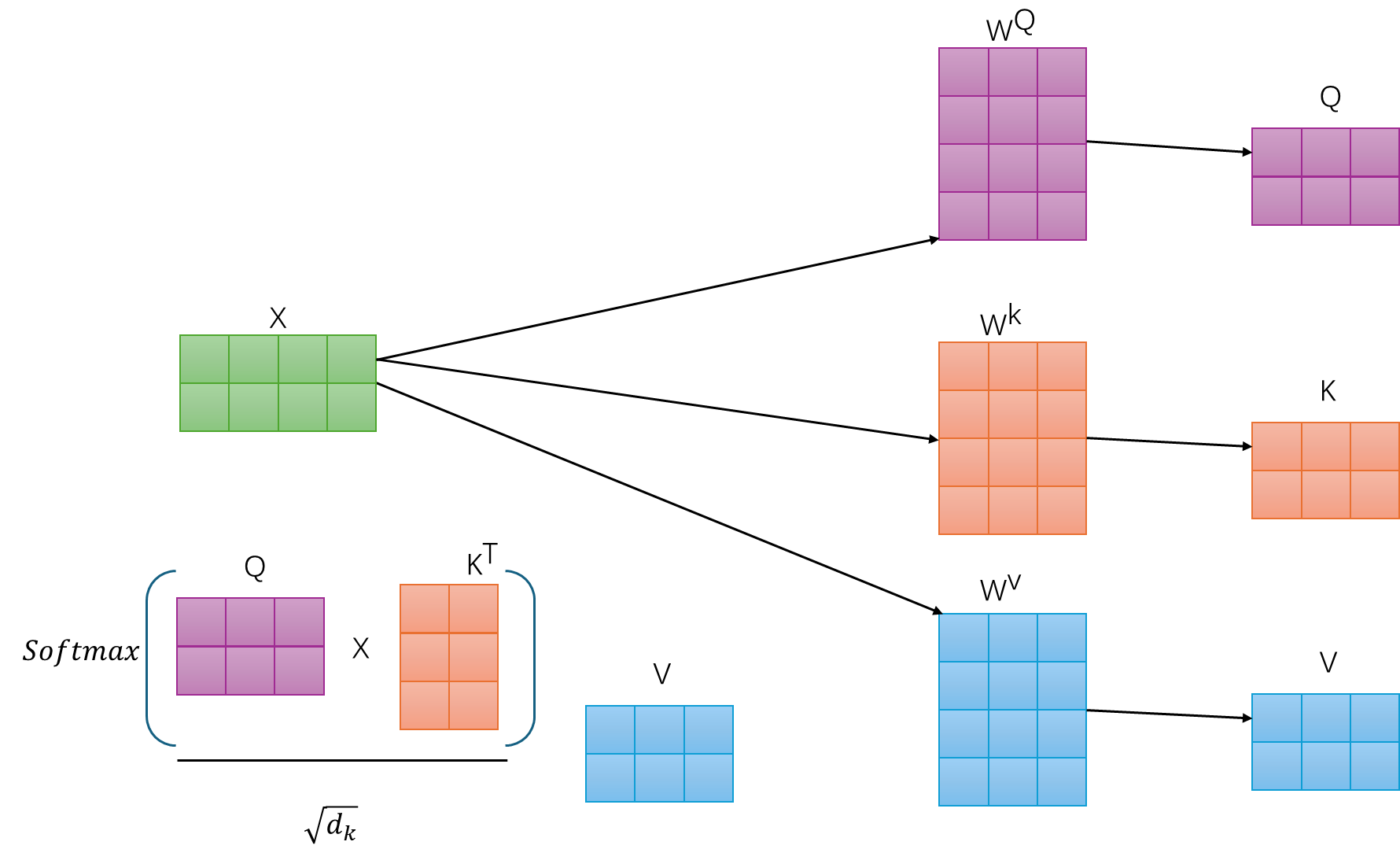
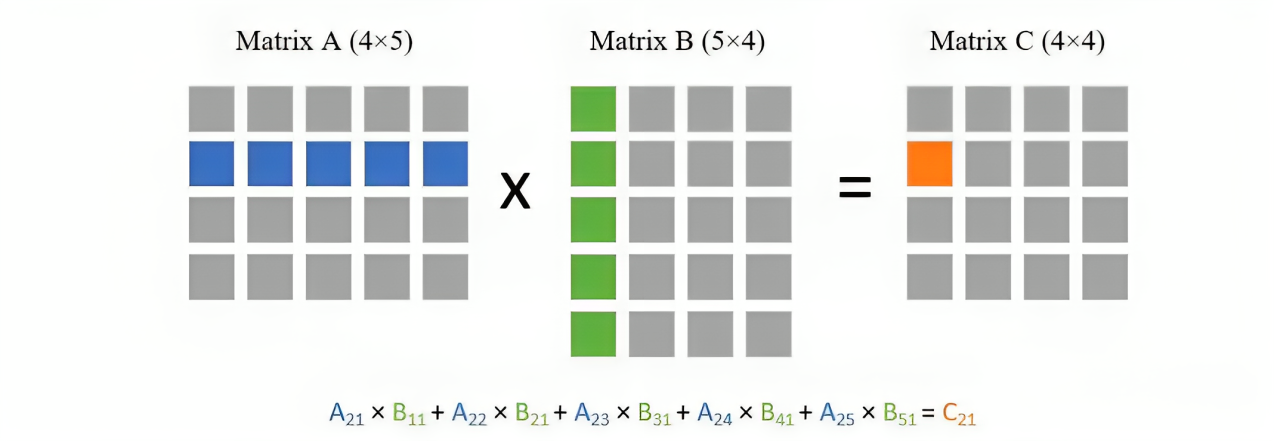
4*5 N*d
因为我们需要拿第一个矩阵的每一行去与第二个矩阵的每一列做点乘,所以总共就需要 次点乘。而每次点乘又需要 次乘法,所以总复杂度就为
精确理解的话,当输入批次大小为 ,序列长度为 时, 层transformer模型的计算量为 , 则代表词向量的维度或者隐藏层的维度(隐藏层维度通常等于词向量维度)
Self-Attention层的计算复杂度
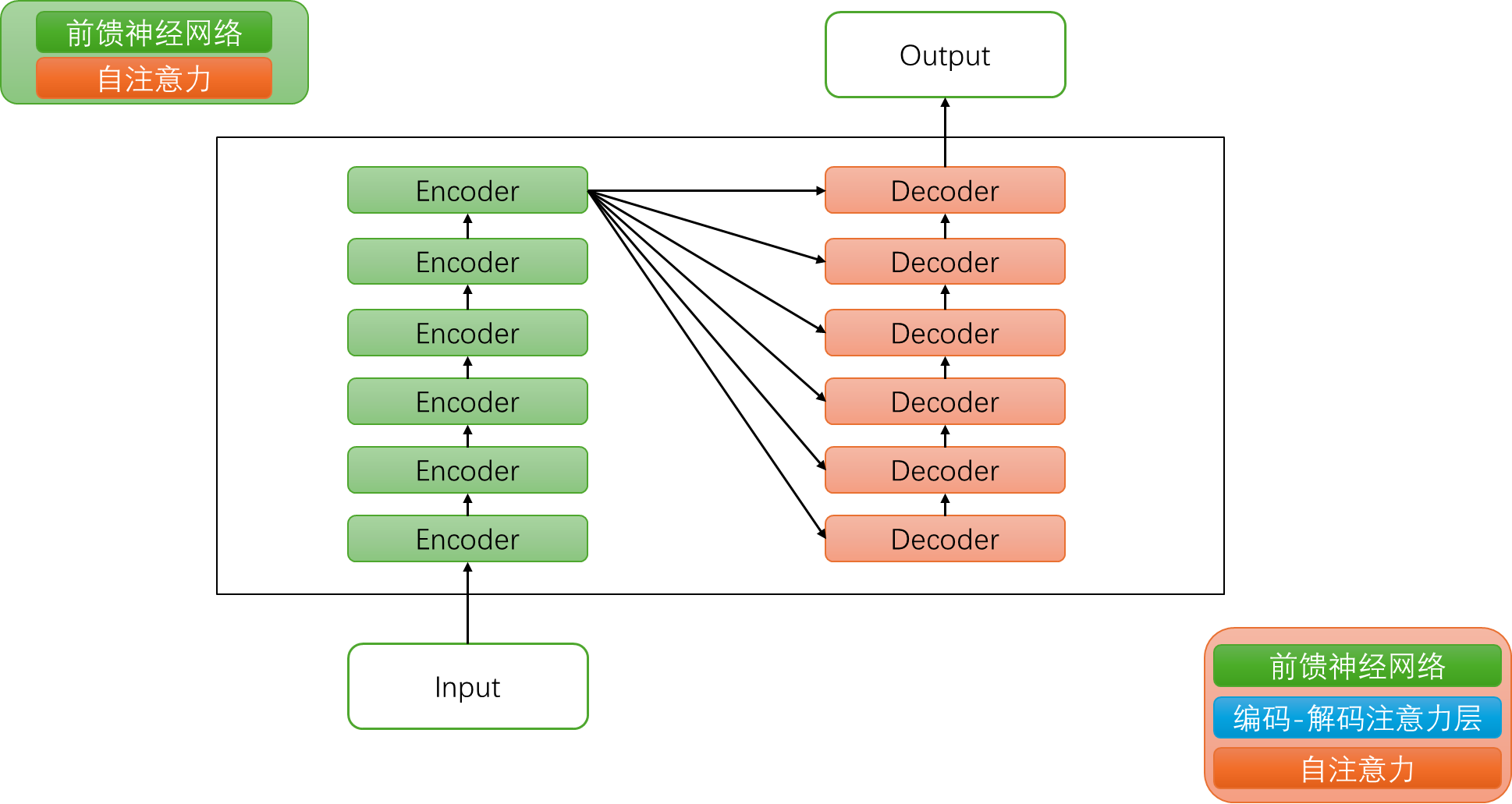
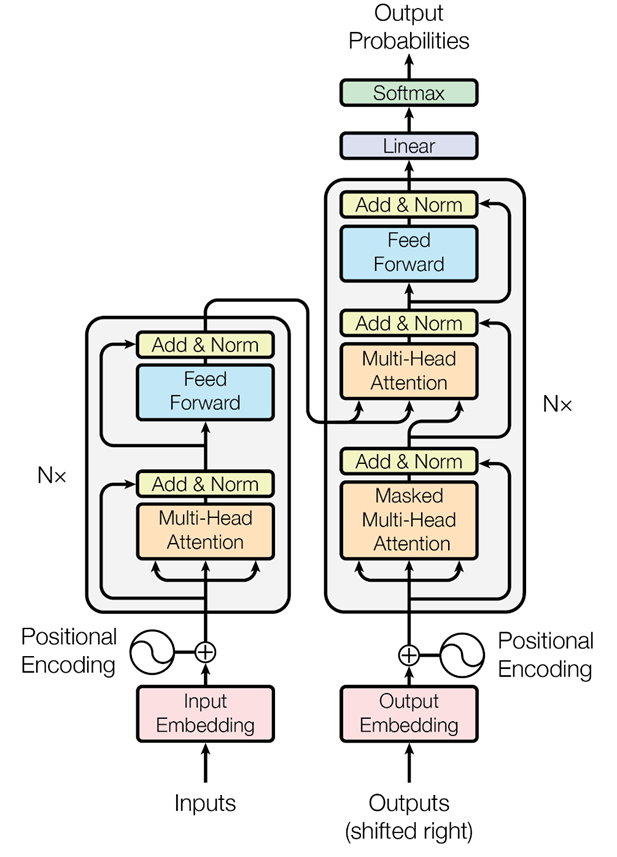
首先,我们知道,transformer模型由 个相同的层组成,每个层分为两部分:self-attention块和MLP块
而self-attention层的模型参数有两部分,一部分是 ,, 的权重矩阵 、、 和偏置,另一部分是输出权重矩阵 和偏置,最终为:
具体怎么计算得来的呢?
- 第一步是计算 、 、
即
该矩阵乘法的输入和输出形状为
计算量为:
(b,N,d)看做b个(N,d),(b,N,d) × (d,d)看做b个(N,d) × (d,d),(N,d) × (d,d)的计算次数是2Ndd(乘法Ndd、加法再Ndd,当然也有的资料不看加法
- 计算
该部分的输入和输出形状为
计算量为:
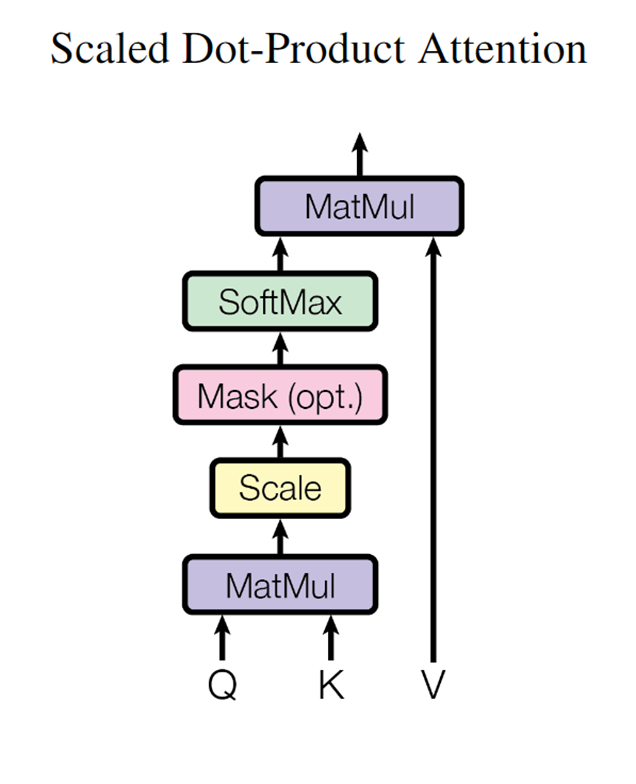
- 计算在 上的加权
该部分矩阵乘法的输入和输出形状为
计算量为:
- attention后的线性映射,矩阵乘法的输入和输出形状为
计算量为
最终自注意力层的输出结果为
MLP层的计算复杂度
MLP块由2个线性层组成,最终是
怎么计算得来的呢?
一般地,第一个线性层是将维度从映射到,第二个线性层再将维度从映射到
- 第一个线性层的权重矩阵 的形状为 ,相当于先将维度从 映射到,矩阵乘法的输入和输出形状为,计算量为
- 第二个线性层的权重矩阵 的形状为 ,相当于再将维度从 映射到 ,矩阵乘法的输入和输出形状为,计算量为
将上述所有表粗所示的计算量相加,得到每个transformer层的计算量大约为
此外,另一个计算量的大头是logits的计算(毕竟词嵌入矩阵的参数量也较多),将隐藏向量映射为词表大小,说白了,词向量维度通常等于隐藏层维度 ,词嵌入矩阵的参数量为,最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的「解释一下,如七月杜老师所说,这个是transformer中一个重要的点,参数共享可以减小参数量,词嵌入矩阵是[vocab_size,hidden_size],输出层矩阵是 [hidden_size,vocab_size],是可以共享的」
其矩阵乘法的输入和输出形状为,计算量为
因此,对于一个 层的transformer模型,输入数据形状为的情况下,一次训练迭代的计算量为上述三个部分的综合,即: